A Practical Guide To Using Golang With Apache Kafka
- With Code Example
- February 25, 2024

Series - Golang With

Are you looking to build scalable, high-performance applications that can process streaming data in real time? If so, combining Apache Kafka and Golang is a great choice. Golang’s lightweight threads make it perfect for writing concurrent network applications like Kafka producers and consumers. Its built-in concurrency primitives like goroutines and channels pair nicely with Kafka’s asynchronous messaging. Golang also has fantastic Kafka client libraries like Sarama that provide idiomatic APIs for working with Kafka.
With Kafka handling the distributed messaging and storage and Golang providing the concurrency and speed, you get a powerful stack for building reactive systems. Processing never-ending streams of data efficiently is a breeze with Kafka’s pub/sub semantics and Golang’s slick concurrency. By leveraging these two technologies together, you can quickly build the next generation of real-time applications for the cloud-native world. So start building your streaming pipelines with Golang and Kafka today!
Apache Kafka is an open-source distributed event streaming platform used for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. It was originally developed by LinkedIn and later became an open-source Apache project in 2011.
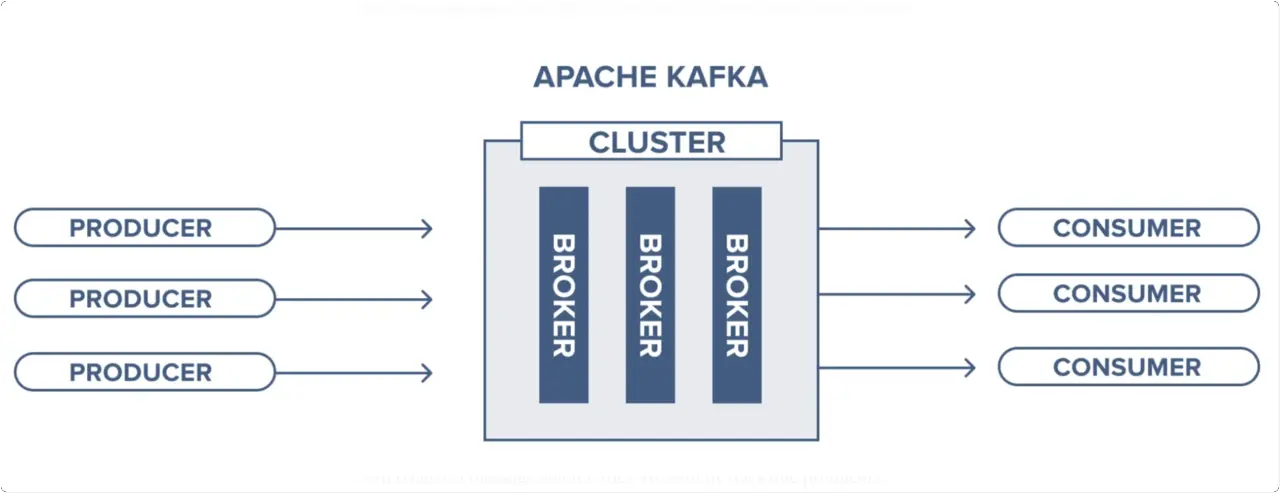
Use Cases and Capabilities of Kafka
Streaming Data Pipelines - Kafka provides a distributed publish-subscribe messaging system that streams data between systems or applications. It offers robust queueing with data replication and fault tolerance.
Real-Time Analytics - Kafka enables processing real-time data streams with tools like Kafka Streams and KSQL for building streaming analytics and data processing applications.
Data Integration - Kafka can be used to integrate disparate systems by streaming data between different data sources and formats. This makes it useful for streaming ETL.
Event Sourcing - Kafka provides a temporal log of events that can be replayed to reconstruct the application state, useful for event sourcing and CQRS patterns.
Log Aggregation - Kafka is commonly used to aggregate logs from different servers and applications into a central repository. This allows unified access to log data.
With its distributed, scalable and fault-tolerant architecture, Kafka is a popular choice for building real-time data pipelines and streaming applications at large scale and is used by thousands of companies worldwide.
Summary
Apache Kafka is an open-source distributed event streaming platform used for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. It offers various capabilities like streaming data pipelines, real-time analytics, data integration, event sourcing, and log aggregation. Combining Golang with Apache Kafka provides a powerful tech stack for building modern applications due to their performance, scalability, concurrency, availability, interoperability, modern design, and developer experience. Getting started with Kafka and Golang involves installing Golang, setting up Kafka, and using the confluent-kafka-go package to build producers and consumers.
Why combining Golang with Apache Kafka
Combining Golang, a highly efficient and concurrent programming language, with Apache Kafka, a distributed event streaming platform, offers a potent technological stack that excels in building cutting-edge modern applications. The synergy between these two technologies stems from several key advantages:
Performance - Both Golang with Apache Kafka offer high performance. Golang is fast, efficient and lightweight. Kafka is built for speed with high throughput and low latency. Together they can handle demanding workloads.
Scalability - Golang’s goroutines and Kafka’s partitioning allow applications to scale horizontally to handle large volumes of data. Kafka effortlessly handles scaling producers and consumers.
Concurrency - Golang provides great concurrent programming capabilities through goroutines and channels. Kafka delivers messages concurrently and supports parallelism.
Availability - Kafka’s distributed architecture makes it highly available and fault tolerant. Golang apps can leverage this to build resilient systems.
Interoperability - Kafka has clients in many languages allowing Golang apps to interact with polyglot environments. Kafka also uses a binary TCP protocol for efficiency.
Modern Design - Both Kafka and Golang use modern design philosophy making them well-suited for cloud-native and microservices architectures.
Developer Experience - Kafka’s client libraries coupled with Goroutines, channels and interfaces make it enjoyable to work with.
Together, Kafka and Golang combine performance, scalability and concurrency with productivity - making them a great choice for building services, pipelines and streaming apps that scale.
Getting Started with Apache Kafka
Before getting started with Golang with Apache Kafka we have to make sure the golang is installed and running on our machine. If not please check out the following tutorial to set up the golang.
Install Golang
Install Kafka
Another important thing is to install Kafka on our local instance, for this I found the official guide to getting started with Apache Kafka.
Apache Kafka Quickstart
You can also follow the youtube tutorial to install apache kafka on windows machine.
Golang package for Apache Kafka
You can install the confluent-kafka-go package using go get:
go get -u github.com/confluentinc/confluent-kafka-go/kafka
Once installed, you can import and use confluent-kafka-go in your Go code.
package main
import (
"fmt"
"github.com/confluentinc/confluent-kafka-go/kafka"
)
func main() {
p, err := kafka.NewProducer(&kafka.ConfigMap{"bootstrap.servers": "localhost:9092"})
if err != nil {
fmt.Printf("Failed to create producer: %s\n", err)
return
}
// Produce messages to topics, handle delivery reports, etc.
// Remember to close the producer after use
defer p.Close()
}
Building a Producer
A Kafka producer, an essential component in the Apache Kafka ecosystem, serves as a client application tasked with publishing (writing) events to a Kafka cluster. This segment provides a comprehensive overview of the Kafka producer, along with an introductory exploration of the configuration settings aimed at fine-tuning its behaviour.

Below is an example of a Golang application that produces data and publishes it to a Kafka topic. It also illustrates how to serialize data in Golang for Kafka messages and demonstrates handling errors and retries.
package main
import (
"fmt"
"github.com/confluentinc/confluent-kafka-go/kafka"
)
const (
kafkaBroker = "localhost:9092"
topic = "test-topic"
)
type Message struct {
Key string `json:"key"`
Value string `json:"value"`
}
func main() {
// Create a new Kafka producer
p, err := kafka.NewProducer(&kafka.ConfigMap{"bootstrap.servers": kafkaBroker})
if err != nil {
fmt.Printf("Failed to create producer: %s\n", err)
return
}
defer p.Close()
// Define the message to be sent
message := Message{
Key: "example_key",
Value: "Hello, Kafka!",
}
// Serialize the message
serializedMessage, err := serializeMessage(message)
if err != nil {
fmt.Printf("Failed to serialize message: %s\n", err)
return
}
// Produce the message to the Kafka topic
err = produceMessage(p, topic, serializedMessage)
if err != nil {
fmt.Printf("Failed to produce message: %s\n", err)
return
}
fmt.Println("Message produced successfully!")
}
func serializeMessage(message Message) ([]byte, error) {
// Serialize the message struct to JSON
serialized, err := json.Marshal(message)
if err != nil {
return nil, fmt.Errorf("failed to serialize message: %w", err)
}
return serialized, nil
}
func produceMessage(p *kafka.Producer, topic string, message []byte) error {
// Create a new Kafka message to be produced
kafkaMessage := &kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Value: message,
}
// Produce the Kafka message
deliveryChan := make(chan kafka.Event)
err := p.Produce(kafkaMessage, deliveryChan)
if err != nil {
return fmt.Errorf("failed to produce message: %w", err)
}
// Wait for delivery report or error
e := <-deliveryChan
m := e.(*kafka.Message)
// Check for delivery errors
if m.TopicPartition.Error != nil {
return fmt.Errorf("delivery failed: %s", m.TopicPartition.Error)
}
// Close the delivery channel
close(deliveryChan)
return nil
}
This example demonstrates how to:
- Create a Kafka producer.
- Serialize a custom message struct (
Message) to JSON using thejson.Marshalfunction. - Produce the serialized message to a Kafka topic using the producer.
- Handle errors and retries using delivery reports and error checking.
Make sure to replace localhost:9092 with the address of your Kafka broker, and test-topic with the desired topic name. Additionally, you may need to handle more complex error scenarios and implement retry logic based on your specific requirements.
Apache Kafka Documentation
Building a Consumer
Kafka consumers are like little event processors that fetch and digest streams of data. They subscribe to topics and consume whatever new messages arrive, handling each one. We’ll explore how these consumers work under the hood and the configuration knobs for tuning their performance. Get ready to level up your skills for building scalable data-driven applications!
Below is an example of a Golang application that consumes messages from a Kafka topic. It includes explanations on how to process and handle consumed messages, as well as discussions on different consumption patterns such as single consumer and consumer groups.
package main
import (
"fmt"
"os"
"os/signal"
"github.com/confluentinc/confluent-kafka-go/kafka"
)
const (
kafkaBroker = "localhost:9092"
topic = "test-topic"
groupID = "test-group"
)
func main() {
// Create a new Kafka consumer
c, err := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": kafkaBroker,
"group.id": groupID,
"auto.offset.reset": "earliest",
})
if err != nil {
fmt.Printf("Failed to create consumer: %s\n", err)
return
}
defer c.Close()
// Subscribe to the Kafka topic
err = c.SubscribeTopics([]string{topic}, nil)
if err != nil {
fmt.Printf("Failed to subscribe to topic: %s\n", err)
return
}
// Setup a channel to handle OS signals for graceful shutdown
sigchan := make(chan os.Signal, 1)
signal.Notify(sigchan, os.Interrupt)
// Start consuming messages
run := true
for run == true {
select {
case sig := <-sigchan:
fmt.Printf("Received signal %v: terminating\n", sig)
run = false
default:
// Poll for Kafka messages
ev := c.Poll(100)
if ev == nil {
continue
}
switch e := ev.(type) {
case *kafka.Message:
// Process the consumed message
fmt.Printf("Received message from topic %s: %s\n", *e.TopicPartition.Topic, string(e.Value))
case kafka.Error:
// Handle Kafka errors
fmt.Printf("Error: %v\n", e)
}
}
}
}
This example demonstrates how to:
- Create a Kafka consumer.
- Subscribe to a Kafka topic.
- Set up a channel to handle OS signals (such as SIGINT) for graceful shutdown.
- Start consuming messages from the subscribed topic.
- Process and handle consumed messages, as well as Kafka errors.
Different consumption patterns:
Single Consumer:
In this pattern, a single consumer instance reads messages from one or more partitions of a topic. This is useful when you only need one instance of your consumer application to process all messages from a topic.
Consumer Groups:
Consumer groups allow you to scale out consumption by distributing message processing across multiple consumer instances. Each consumer group can have multiple consumers, and each consumer within the group reads from a subset of partitions. This enables parallel processing of messages, providing both fault tolerance and high throughput.
In the provided example, the group.id configuration setting is used to specify the consumer group ID. This allows multiple instances of the consumer application to work together in a consumer group to consume messages from the Kafka topic.
Conclusion:
In conclusion, Apache Kafka serves as a robust solution for building real-time data pipelines and streaming applications due to its distributed, scalable, and fault-tolerant architecture. When combined with Golang, it forms a powerful tech stack that excels in performance, scalability, and concurrency, making it ideal for modern applications. By leveraging Kafka’s capabilities and Golang’s strengths, developers can build resilient and high-performance services, pipelines, and streaming applications that scale effortlessly to meet the demands of today’s data-driven world. Whether it’s processing real-time analytics, integrating disparate systems, or aggregating logs, Kafka and Golang provide a winning combination that enables developers to build innovative and scalable solutions with ease.
FAQs
Apache Kafka is an open-source distributed event streaming platform used for building real-time data pipelines and streaming applications. It is designed to handle high-throughput, fault-tolerant, and scalable data streams.
Golang (or Go) is well-suited for building high-performance, concurrent, and scalable applications. When combined with Apache Kafka, Go enables developers to efficiently process and handle large volumes of streaming data.
You can use the sarama library, which is a Go client for Apache Kafka. It provides a simple and efficient way to produce and consume messages from Kafka topics in Go applications.
You can install the sarama library using the following go get command:
go get github.com/Shopify/sarama
You can produce messages to a Kafka topic using the sarama library by creating a Producer and then sending messages to the desired topic.
You can consume messages from a Kafka topic using the sarama library by creating a Consumer and then subscribing to the desired topic to receive messages.
Some best practices include properly handling errors, configuring appropriate Kafka client settings, implementing message serialization and deserialization, and ensuring proper resource management.
Yes, you can use Golang with Kafka Streams for building stream processing applications. Although Kafka Streams is primarily a Java library, you can interact with it using Go by leveraging Kafka’s protocol and APIs.
You can refer to the official documentation of the sarama library, explore tutorials and examples online, join developer communities and forums, and consider reading books or articles on Kafka and Golang integration.
Related Posts



Hooks and Callbacks in GORM
Download PDF In the realm of database management, customization is key to crafting efficient and tailored workflows. GORM, the dynamic Go Object-Relational Mapping library, empowers developers with hooks and callbacks, offering a way to inject custom logic into various stages of the database interaction process.


